Limited Direct Execution
cpu를 가상화할때 필요한 mechanism에 대해서 알아보자.
여기서 direct라는 것은 사용자 프로그램이든, 커널이든 상관없이 cpu가 직접 처리한다는 의미이고, 성능때문에 그렇게 하고있지만 이렇게 될 경우 운영체제가 cpu를 직접 컨트롤(스케줄링)할수 없게 되는 문제가 생긴다.
그런데 운영체제 입장에서는 cpu를 하나의 자원으로 보고 적절히 스케줄링할 수 있어야 하기 때문에 성능손실 없이 cpu를 컨트롤하기 위해서 고안된 것이 바로 Limited Direct Execution(제한적 직접 실행)이라는 메커니즘이다.
cpu가 물리적으로는 하나지만 모드는 두개가 있다. (user mode, kernel mode)
그리고 이 모드를 어떻게 설정하느냐에 따라서 cpu가 완전히 다른 기계처럼 동작한다.
kernel mode는 privileged mode로서, cpu가 할 수 있는 모든 일을 한다. 예를 들어 interrupt처리나 io관련된 처리는 전부 kernel mode에서만 할 수 있는 일이다. cpu가 어떤 일을 할 수 있다는 것은 특정 명령어가 보여서 실행할 수 있다는 뜻이기 때문에, 위에서 언급한 특별한 처리를 위한 명령어들은 kernel mode에서 명령어의 full set이 다 보이는 것이고, user mode에서는 이 처리들과 관련된 명령어가 보이지 않게 함으로써 이 두 모드를 구별짓고 있다.
그럼 kernel mode에서만 보이는 이 명령어들을 어떻게 user program이 호출해서 사용할까?
운영체제가 컨트롤 할 수 있는 선에서 이걸 가능하게 하는 방법이 system call이다.
우리가 흔히 보는 read(), write(), open(), close()등 파일과 관련된 함수들이 바로 system call의 일종이다.
Trap
cpu가 user mode에서 user code를 실행하다가 갑자기 뭔가에 걸려서 kernel mode의 kernel code를 실행하게 되는 것을 trap이라고 하고, 마치 cpu가 함정에 빠진것같다고 해서 그렇게 부른다.
trap의 원인은 여러개이고, 각 원인에 따라 처리해줘야 하는 방법도 각각 다르다. 때문에 그 원인과 해줘야 하는 일을 테이블로 관리하는 trap table을 kernel에 구성하고 있다.
그리고 trap에 빠지면 일단 trap이 왜 걸린건지 그 이유를 판단하는 trap handler도 존재한다.
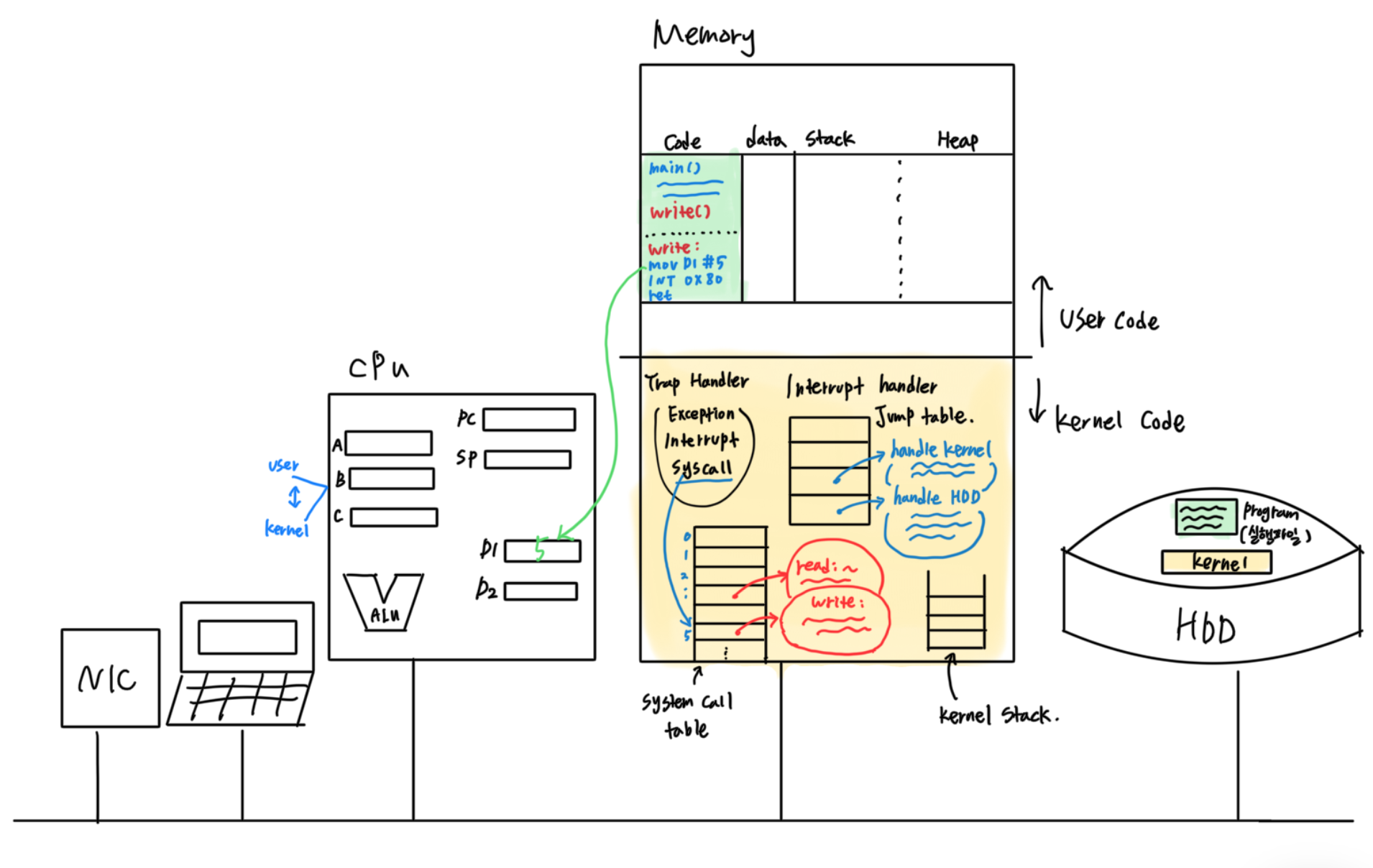
우선 trap이 발생하는 과정을 이해하기 위해서 전체 구조를 생각해보자.
cpu가 물리적으로는 하나지만, 마치 스위치가 있어서 user mode, kernel mode를 왔다갔다할 수 있는것같이 동작한다.
user mode일 때는 시스템 전반적인 interrupt, io관련 명령어 자체가 아예 없는것처럼 보이기 때문에, cpu는 두가지 모드를 왔다갔다 하면서 작동한다.
또 메모리 역시 user code부분과 kernel code가 분리되어 있다. (user code는 로딩할때, kernel code는 부팅할때 올라온다.)
이 kernel code부분에는 trap을 처리하는 trap handler뿐만 아니라, indirect jump를 하는 jump table 역시 존재한다. 이 jump table의 원소들은 포인터 값이 되고, 그 포인터를 따라가보면 뭔가를 처리하는 코드가 있게 된다.
또한 exception과 interrupt를 처리하는 interrupt handler table, system call을 처리하는 system call table도 kernel code에 포함되어 있다. system call table에는 몇백개가 넘는 많은 원소들이 있는데 각각을 호출하는 시간은 동일하다. 시작주소와 offset을 알면 indirect jump를 하므로 찾아가는 시간은 동일한 것이다.
cpu의 pc가 user code를 실행하고있을때 cpu는 user mode로 있게되고, user code를 실행하다가 kernel code를 실행해야 할 일이 생기면 pc가 kernel code부분을 가리켜서 실행해야한다. 이 경우에는 cpu가 kernel mode로 바뀌게 된다. 바로 이때 trap이 발생하는 것이다.
cpu가 user code를 실행하다가 갑자기 trap에 걸리게 되면 pc가 미리약속된 지점, trap handler의 위치로 바뀐다.
trap handler의 위치는 고정되어있어서 cpu가 알고있고, trap이 생긴 시점에 자동으로 이 주소가 pc로 들어가게 된다.
trap이 걸리는 원인은 크게 3가지이다.
- exception발생 (internal interrupt) : cpu, memory에서 에러가 발생
- interrupt (external interrupt) : cpu, memory 그 외 외부장치에서 예외상황이 발생
- syscall : INT(interrupt) 명령어같은 software trap
이런 원인들에 의해 trap이 걸리면 pc가 trap handler로 위치를 바꾼다.
trap handler에서는 trap이 걸린 원인을 알아내고, 그에 따라 해당 원인에 맞는 서비스를 하도록 점프한다.
Limited Direct Execution 예시

1. process가 생성되어서 process목록에 등록이 되고, 그를 위한 공간이 메모리에 배치된다. 프로그램을 메모리에 로딩하고 적절한 값으로 user stack을 채운다. 초기값으로 사용하고 싶은 register값들과 pc로 kernel stack을 채운다.
2. trap에서 return할 경우(return from trap), kernel stack에 있는 내용을 가지고 cpu의 register들을 덮어쓴다(restore). cpu를 user mode로 전환한다. 이때, pc(=ip)도 stack에 들어있었기 때문에, 메인함수를 위한 pc를 넣어놨다면 main함수로 점프한다.
3. user mode로 전환되어 main()을 실행한다. 그러다가 system call을 호출하면 trap이 걸려 kernel로 다시 넘어가게 된다. 예를 들어 write()함수를 호출했다면 그 내부적으로는 sofrware trap인 INT명령어가 존재하기 때문에 trap에 걸리게 되는 것이다.
4. 이때 kernel stack에 현재 레지스터값들을 저장해두고 kernel mode로 전환한다. user code를 가리키던 pc는 갑자기 trap handler로 확 점프해서 넘어간다.
5. kernel mode로 trap을 처리하고 return from trap.
6. kernel stack에 있던 register를 cpu로 복원하고 cpu를 user mode로 전환한다. 기존에 저장해두었던 pc로 점프한다.
7. 프로그램을 모두 실행하고 exit()호출. trap에 걸려서 kernel로 넘어감.
8. 프로세스의 메모리공간을 정리하고, 프로세스 리스트에서도 해당 프로세스를 제거한다.
Context switching
이처럼 user program이 실행되다가 kernel로 컨트롤이 넘어가야 kernel이 cpu라는 제한된 자원을 나눠쓸 수 있도록 스케줄링한다.
그리고 context switching은 kernel안에서만 일어난다. old process가 진행되다가 new process가 진행되기 위해서는 우선 old process가 커널로 진입해야한다는 뜻이다.
이때 컨트롤이 kernel로 넘어가는 방법은 두가지이다.
user program이 cooperative하거나(정기적으로 system call을 호출해줌), 운영체제가 timer에 의해 interrupt를 걸어서 모든 것을 컨트롤하거나.
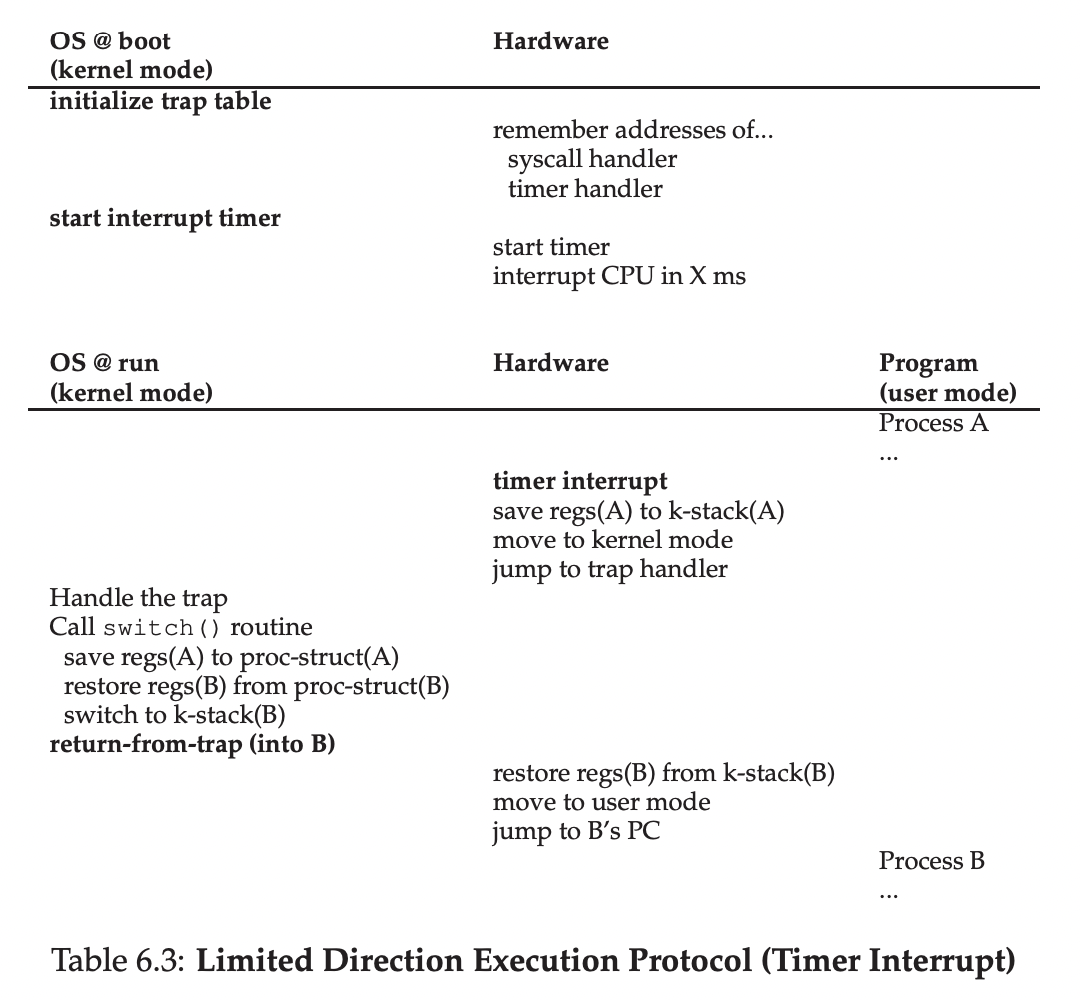
# void swtch(struct context **old, struct context *new);
#
# Save current register context in old
# and then load register context from new.
.globl swtch
swtch:
# Save old registers
movl 4(%esp), %eax # put old ptr into eax
popl 0(%eax) # save the old IP
movl %esp, 4(%eax) # and stack
movl %ebx, 8(%eax) # and other registers
movl %ecx, 12(%eax)
movl %edx, 16(%eax)
movl %esi, 20(%eax)
movl %edi, 24(%eax)
movl %ebp, 28(%eax)
# Load new registers
movl 4(%esp), %eax # put new ptr into eax
movl 28(%eax), %ebp # restore other registers
movl 24(%eax), %edi
movl 20(%eax), %esi
movl 16(%eax), %edx
movl 12(%eax), %ecx
movl 8(%eax), %ebx
movl 4(%eax), %esp # stack is switched here
pushl 0(%eax) # return addr put in place
ret # finally return into new ctxt위의 코드는 스위치가 일어날 때 호출되는 swtch()함수이고, 이 함수가 호출되었을 때의 execution stack은 다음과 같다.
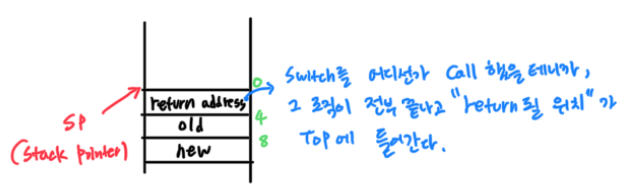
swtch라는 함수가 실행되려면 그 함수를 위한 activation record가 생성되어야 하는데, 우선 두번째 파라미터, 첫번째 파라미터가 들어가고, 진짜로 이 함수가 호출되면 그때 이 함수의 리턴 위치를 stack의 top에 넣는다.
그래서 전체적인 context switching의 과정을 살펴보면
1. 유저영역에서 실행중이던 old process의 정보들이 kernel stack에 들어간다(커널로 진입). 이후 new process작업이 끝나고 다시 이 프로세스가 실행될때, 여기에 저장해둔 유저영역의 실행정보가 복구된다.
2. old process > new process로 context switching이 일어나기 위해서는 old process의 커널영역 정보들을 old process의 pcb에 저장한다. 이때 유저영역의 정보는 저장하거나 복구하지 않는데, 이것은 old process의 유저영역 정보는 커널 진입시에 kernel stack에 이미 넣어뒀기 때문이다.
3. new process의 커널영역 정보를 new process의 pcb에서 가져와서 cpu를 복원하고
4. 마지막으로 new process의 kernel stack에 저장되어있는 유저영역의 정보를 복원하며 user mode로 돌아간다.
즉, 전반부에는 cpu의 정보를 kernel stack에 옮기고 + 또 pcb의 context에 옮겨두고 (두번 들어간다), 후반부에는 new process의 정보들을 pcb의 context에서가져오고, kernel stack에서 또 가져와 cpu를 새롭게 초기화하는 일이 일어난다.
pcb(process control block)에 저장되는 값과 kernal stack에 저장되는 값의 차이가 뭘까?
pcb와 kernel stack에 저장되는 정보는 그 생김새는 같아도(레지스터값, 프로세스상태값 등) 내용은 다르다.
kernel stack에 있는 값 = cpu가 머신사이클 돌고 이순간에 왔을때 그 순간의 값.
pcb에 있는 값 = context switching이 일어날때 그 순간의 값.
즉, 정보가 저장되는 순간이 달라서 그 값도 다르다.
* 2023 국민대학교 소프트웨어학부 황선태 교수님의 운영체제 수업을 듣고 정리한 내용입니다.
* 원서 출처 : https://pages.cs.wisc.edu/~remzi/OSTEP/
'운영체제' 카테고리의 다른 글
| Scheduling: The Multi-Level Feedback Queue (MLFQ) (2) | 2023.03.21 |
|---|---|
| Scheduling: FIFO, SJF, STCF, Round Robin, incorporation IO (0) | 2023.03.20 |
| process API (system call) (0) | 2023.03.12 |
| The Abstraction : The process (0) | 2023.03.12 |
| Virtualizing CPU,Memory/ Concurrency/ Persistence (0) | 2023.03.07 |