Scheduling Metrics
context switching이 일어날 때, 새로운 프로세스는 어떻게 결정되는가?
바로 스케줄링 정책(scheduling policies)에 의해서이다.
그리고 이 정책이 어떤지 판단하는 기준이 바로 Scheduling Metrics이다.
이 metric에는 성능측면(performance)에서 바라보는 기준, 공평한가의 측면(fairness)에서 바라보는 기준이 있는데 각각 밑에서 알아보겠다.
1.turnaround time(반환시간)
turnaround time = completion time - arrival time
반환시간이란 해당 job이 도착했을 때부터 cpu를 다 사용해서 끝났을때까지 걸리는 시간이다.
(job이 끝난 시간 - 도착한 시간)
그리고 반환시간은 성능 측면(performance)에서의 metric이다.
2.response time(반응시간)
response time = first run time - arrival time
반응시간이란 해당 job이 도착해서 처음으로 스케줄링되기까지 걸리는 시간이다.
(job이 처음 스케줄링된시간 - 도착한 시간)
그리고 반응시간은 공평성 측면(fairness)에서의 metric이다.
turnaround time (반환시간)
성능 측면의 Metric에 따른 스케줄링 정책들
1.FIFO (first in first out)
먼저 들어온 job을 먼저 처리하는 방식이다.
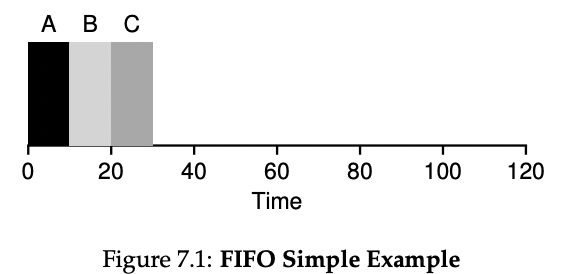
여기 동시에 도착한 A,B,C 세개의 job이 있다. (셋이 동시에 도착했다면 아무거나 먼저 처리한다.)
이때 반환시간은 (10-0) + (20-0) + (30-0)을 3으로 나눈 20이다.

그런데 A,B,C가 처리해야 하는 양에 크게 차이가 날때 문제가 생긴다.
A같이 아주 큰 job이 들어왔는데 안타깝게도 이게 제일 먼저 처리된다면 b,c는 cpu를 조금밖에 안쓰는 job인데도 100이나 기다렸다가 실행된다.
이때 반환시간은 (100-0) + (110-0) + (120-0)을 3으로 나눈 110이 된다.
2.SJF(shortest job first)
가장 짧은 job을 먼저 처리하는 방식이다.

B,C가 A보다 짧은 job이기 때문에 먼저 수행하게 된다.
이때 반환시간은 10+20+120을 3으로 나눈 50이 된다.
fare한 방법은 아니지만, 모든 job이 동시에 도착한다면 반환시간에 있어서는 SJF가 최적의 방법이다.
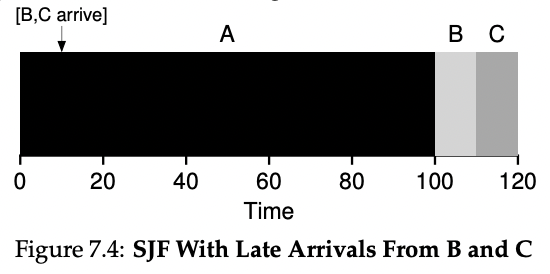
하지만 만일 long job이 먼저와서 실행하는 중에 short job이 뒤늦게 도착하게 된다면 이는 short job임에도 꼼짝없이 앞의 job 실행이 끝날때까지 오래 기다려야 한다는 한계가 있다.
이 스케줄링 정책에서는 한번 job을 시작하면 중간에 끊을 수 없다는 것을 보장하기 때문이다.
이 경우의 반환시간은 (100-0) + (110-10) + (120-10)을 3으로 나눈 103.33이 된다.
이런 문제를 개선하기 위해 한번 job이 시작하면 끝날때까지 계속하는 방식을 수정하게 되는데 이것이 STCF이다.
3.STCF(shortest time to completion first)
지금부터 job이 끝날때까지의 길이를 따져서 남은 시간이 가장 짧은 job을 먼저 실행하는 방식이다.

새로운 job이 도착하면, 그 job이 끝나기까지 걸리는 시간과 현재 실행중인 job이 끝나기까지 걸리는 시간을 비교하여, 더 짧은 것을 먼저 처리한다. 위의 경우에 반환시간은 (120-0) + (20-10) + (30-10)을 3으로 나눈 50이 된다.
이렇게 STCF에서는 모든 job이 동시에 도착하지 않아도 반환시간이 최적이다.
다시 말해, long job인 A가 먼저 와서 끝까지 실행되면서 다른 short job들의 실행을 막는 불합리함이 극복되는 것이다.
* 그런데 SJF, STCF와 같은 정책들이 현실적으로 가능한 것은 아니다. job의 실행시간은 실제로 실행해보기 전엔 알 수 없기 때문이다. 이를 보완하는 방법은 다음 포스팅에서 정리하도록 하겠다.
response time (반응시간, 응답시간)
공평함 측면의 Metric에 따른 스케줄링 정책들
1.RR(round robin)
여러개의 job을 잘게 나누어 cpu를 돌아가면서 사용하게 하는 방식이다.

이렇게 round robin같은 정책이 구현될 수 있는 것은 Timer라는 장치에 의해 주기적으로 interrupt를 걸 수 있기 때문이다. 즉, 위 그림의 경우, timer를 1ms로 설정하고 주기적인 trap을 발생시켜서 context switching을 일으키는 것이다.
또한 timer의 간격을 더욱 세분화하면 respond time을 더 줄일수도 있다.
이렇게 이 방식은 fare하고 response time기준으로는 좋지만, turnaround time기준으로는 매우 좋지 않다.
그리고 context switching이 일어날때 스케줄링 함수를 호출하는 절차에서 드는 비용이 하드웨어적으로 overhead라는 단점도 있다.
이러한 overhead까지 고려한다면 실제 들어가는 시간은 이론적인 것보다 더 늦춰질수도 있다는 것이다.
Incorporationg IO
CPU의 사용률을 최대화하기 위해 IO연산을 고려하는 스케줄링 방법
프로세스가 write()과 같은 system call을 스스로 호출하여 blocked되면 그 사이에 ready상태인 다른 프로세스를 스케줄링하는 방법이다.

위의 그림을 보면 IO요청 때문에 A가 cpu를 쓸 수 없는 그 시간에 B가 대신 cpu를 사용한다. 이렇게 CPU와 IO가 오버랩되는 것을 허용함으로써 cpu를 더 효율적으로 사용할 수 있게 되는 것이다. (이 경우 성능이 40%이상 개선됨)
이 과정을 좀 더 자세하게 살펴보자.
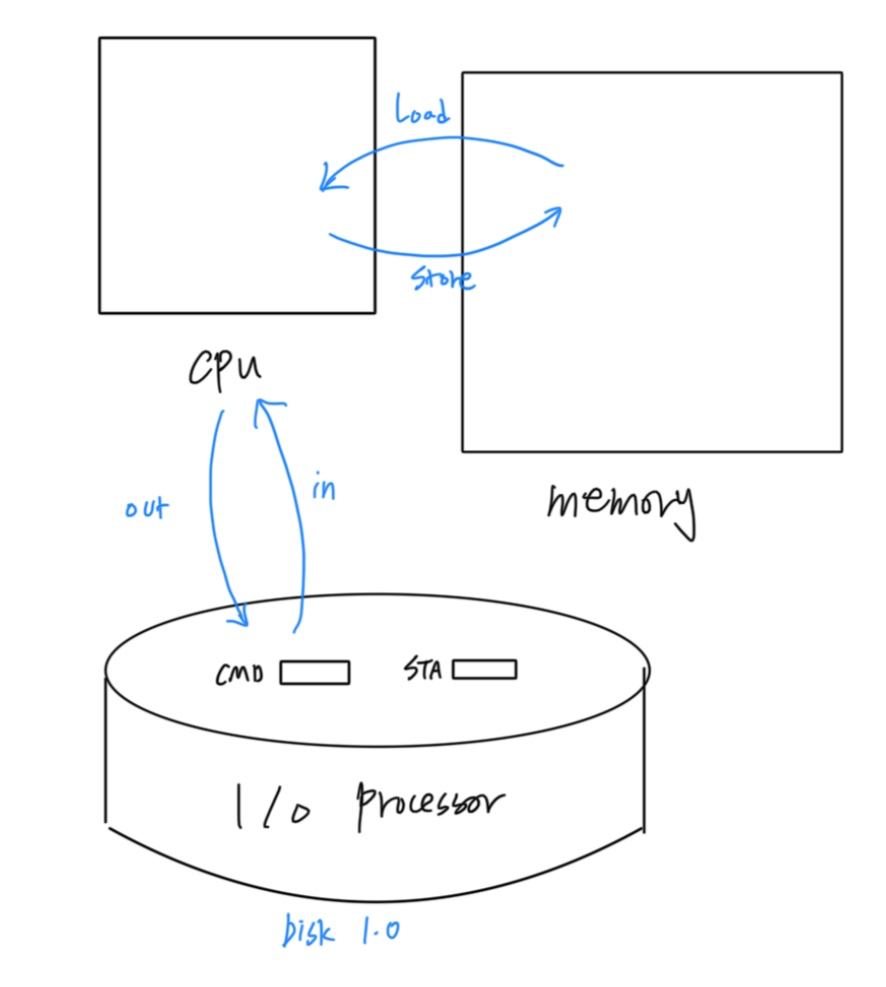
cpu가 memory에서 값을 읽어오거나 memory에 값을 쓸때는 Load, Store명령을 통해서 한다.
또한 cpu에 있는 레지스터 값을 IO processor로 이동할때는 Out, IO processor에서 상태정보를 읽어올때는 In명령을 쓴다.
그래서 예를 들어 running중인 어떤 프로세스가 write()라는 system call을 수행한다면, cpu는 이 명령을 io processor로 보내는 out()명령을 수행할때까지만 개입하고, 그 이후에는 이 작업이 다 끝날때까지 더이상 할 일이 없어진다.
이렇게 이 프로세스는 running > blocked상태가 되고, 운영체제는 다시 스케줄링을 해서 ready상태인 다른 프로세스와 switch시킨다.
한편, IO processor에서 IO요청에 의한 작업이 끝나면 이 IO processor(disk io)가 cpu에게 interrupt을 걸고, 그 interrupt처리를 한 시점에서 blocked된 프로세스는 다시 ready상태로 변한다.
* 2023 국민대학교 소프트웨어학부 황선태 교수님의 운영체제 수업을 듣고 정리한 내용입니다.
* 원서 출처 : https://pages.cs.wisc.edu/~remzi/OSTEP/
'운영체제' 카테고리의 다른 글
| Scheduling: Proportional Share (0) | 2023.03.21 |
|---|---|
| Scheduling: The Multi-Level Feedback Queue (MLFQ) (2) | 2023.03.21 |
| Mechanism : Limited Direct Execution (0) | 2023.03.13 |
| process API (system call) (0) | 2023.03.12 |
| The Abstraction : The process (0) | 2023.03.12 |