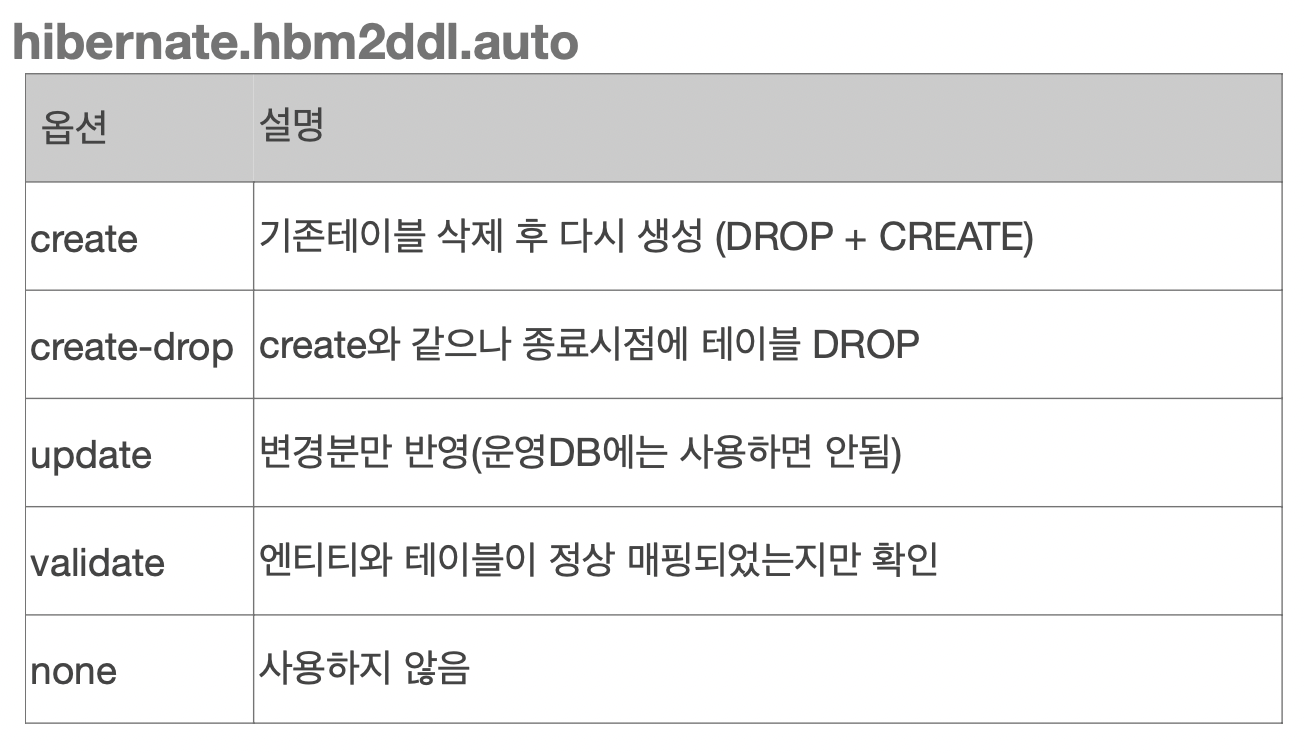
데이터베이스 스키마 자동 생성 jpa에서는 DDL을 애플리케이션 실행 시점에 자동으로 생성해준다. 데이터베이스 방언(dialect)을 이용해서 데이터베이스에 맞는 적절한 DDL을 생성한다. 그리고 이렇게 생성된 DDL은 개발 장비에서만 사용하고 운영서버에서는 사용하지 않는다. (사용하더라도 다듬고 사용) hibernate.hbm2ddl.auto 옵션 create 기존 테이블 삭제 후 다시 생성 (drop + create) create-drop create와 같으나 종료 시점에 테이블 drop update 변경분만 반영(운영 DB에는 사용하면 안됨!) validate 엔티티와 테이블이 정상 매핑되었는지만 확인 none 사용하지 않음. 운영장비에는 절대 create, create-drop, update를 사..